About NAVLIPI
- PRIMER: How are language sounds (phones) classified according to “articulation position” and “phonochromaticity”
- PRIMER: What’s a phoneme?
- What is phonemic idiosyncrasy?
- Why is it important for an alphabet (a script) to be able to convey information on phonemic idiosyncrasy?
- What are the main features of NAVLIPI?
- How does NAVLIPI transcribe phonemic idiosyncrasy?
- What does NAVLIPI Look Like?
- Some more features of NAVLIPI to get a feel for it
PRIMER: How are language sounds (phones) classified according to “articulation position” and “phonochromaticity”
In the context of languages, a phone is any sound created by the human vocal apparatus, such as the b in boy or the k or i in king. It may be a vowel, a “consonant” or an exotic sound like a clicking sound (like the English sound rendered “tsk tsk” in cartoon balloons).
For simplicity, here we limit our discussion to articulation positions of “consonants”, as these are easier to understand than those for vowels and other classes of sounds. “Consonants” can be nearly completely classified using just two variables: Articulation position and phonochromaticity (the “color” of the phone).
The articulation position of a sound is where in the human vocal apparatus it originates or is articulated from. For “consonants”, the figure below helps illustrate common articulation positions in the human vocal apparatus (in the figure, the teeth are colored brown and the tongue is labeled), and what they’re called.
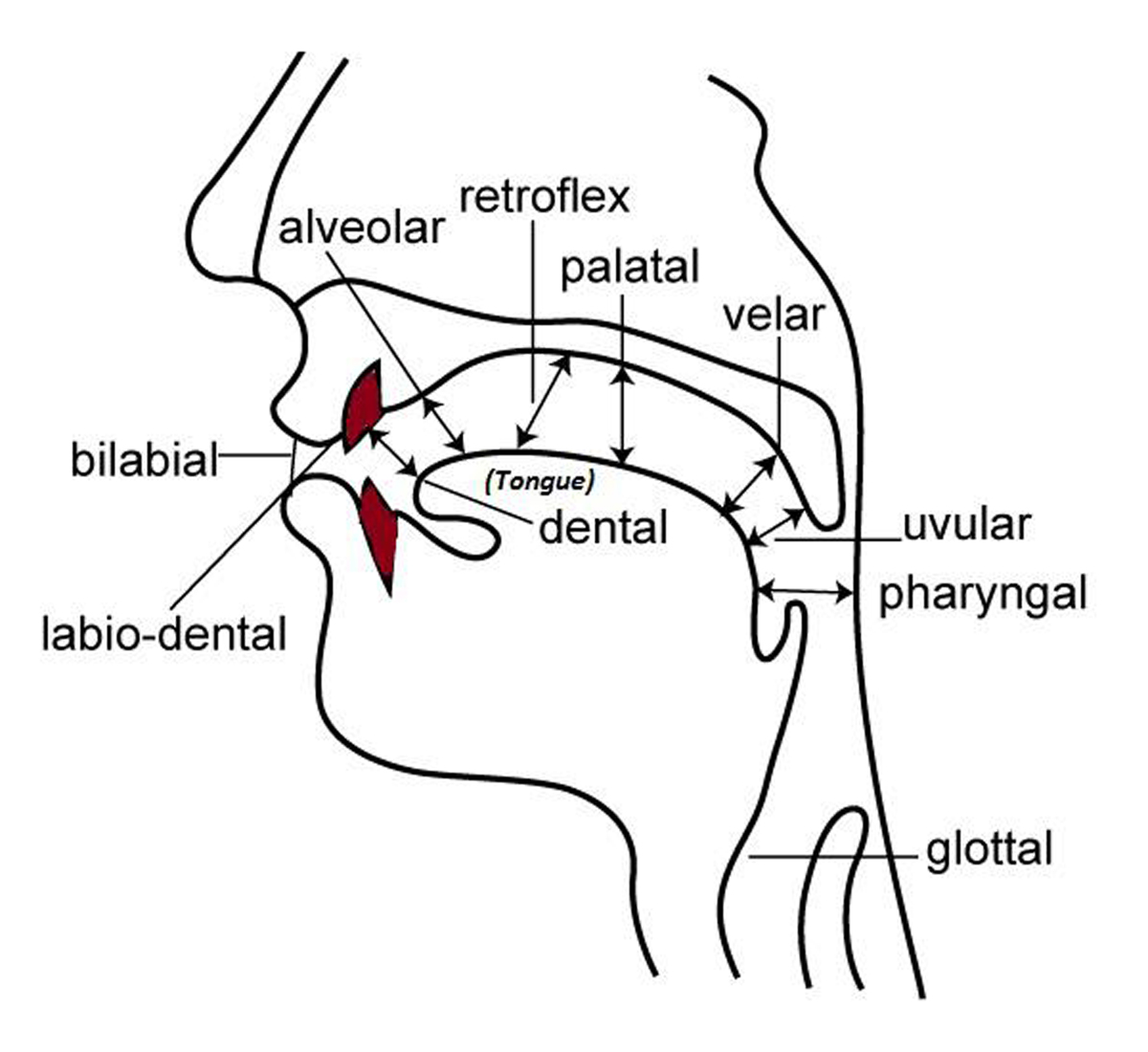
Referring to the figure, some typical phones in English (as an example) can be classified as follows:
- Velar: k as in king.
- Palatal: ch as in child.
- Alveolar: t as in to.
- Labiodental: f as in full.
- Bilabial: p as in pet.
- For Dental, we turn to Spanish t as in tu.
Phonochromaticity, the “color” of the phone, designates the type of phone. Types include, e.g., aspirated, unaspirated, voiced, unvoiced, nasal, fricative, flap (tap), click, etc.. Some of these phonetic terms are self-explanatory: Thus, aspirated phones are uttered with an extra breath, e.g. in ph (aspirated) vs. p (unaspirated). Voiced means the vocal chords vibrate. This can be perceived by simply placing two fingertips on the throat where the Adam’s apple normally is, then uttering in quick succession the pair of sounds k (unvoiced) and g (voiced), or p (unvoiced) and b (voiced), or t (unvoiced) and d (voiced). The vibration of the vocal chords will be clearly perceived when uttering the second sound of each pair, which is voiced. A nasal sound is one in which the breath is expelled through the nose, as in n or m. A fricative is a rubbing, hissing or other frictional sound, as in s or f. A flap or tap is distinguished from a full plosive sound in that the organs of articulation are not fully closed and then suddenly opened, as in a plosive, but rather just lightly tapped or flapped. A click is a sound like the one rendered tsk tsk in English, or the sound one makes to egg on a horse.
PRIMER: What’s a phoneme?
In order to understand NAVLIPI, it is essential for the reader to be very familiar with the concept of a phoneme.
In the context of languages, a phone has been defined above. A phoneme then is a phone with a linguistic significance. A phoneme is unique to a particular language. Two phones can be part of the same phoneme in a language, or they can be distinct, separate phonemes.
A quick test for a phoneme vs. a phone is as follows: If, in a particular language, upon substitution of one phone by another in a word, the meaning of the word changes, then the two phones are separate, distinct phonemes in that language. On the other hand, if such substitution does not change the meaning of the word, then the two phones are part of the same phoneme. Thus in English, the phones p and b, as in the words pit and bit, are distinct phonemes, since substitution of the p by the b in these words completely changes their meaning. On the other hand, in Mandarin, if one says pu or bu, or Beijing or Peijing, it doesn’t change the meaning of the word; so the phones p and b are part of the same phoneme in Mandarin. Similarly, the phones [p] (unaspirated) and [ph] (aspirated) are components of the same phoneme in English, since substitution of one by the other does not change meanings of words: E.g. in the word put, the p can be pronounced with ([ph]) or without ([p]) aspiration. However, [p] and [ph] are different phonemes in Hindi/Urdu, since substitution of one by the other does change the meanings of words entirely: e.g. pal, “an instant” vs. phal “fruit”. In English, [p] and [ph] are said to be allophones of the same phoneme. In Western linguistic terminology, phonemes are designated by forward slashes: thus, the phoneme incorporating the [p] and [ph] sounds in English is designated as /p/. In contrast, in Hindi/Urdu, where these two sounds are distinct phonemes, we designate /p/ and /ph/.
What is phonemic idiosyncrasy?
Phonemic idiosyncrasy can be defined as the existence of very different sets (usually, pairs) of phones as allophones of the same phoneme in one language, whereas the same phones exist as distinct phonemes in another language. One example is that cited above: The bilabial sound [p] and its aspirated counterpart, [ph], are allophones of the same phoneme, /p/, in English, whereas they are distinct phonemes in Hindi/Urdu. Another example is the unvoiced and voiced bilabial phones, [p] and [b], which are allophones of the same phoneme in many Chinese languages. That is to say, one can say Beijing or Peijing, or pu or bu, without change of meaning, in a Chinese language like Mandarin. On the other hand, [p] and [b] are of course different phonemes in most Indo-European languages. E.g. in English, pet and bet have entirely different meanings. As yet other examples of peculiar allophones found in some languages, we can cite [x] (uvular/velar fricative, the famous “uvular r ” or “throaty r” of Parisian French and also much modern German, a sound coming from deep within the throat), and [r], the rolled or trilled r-sound. These are two radically different phones of modern French and German. Here, the first phone is a velar or uvular fricative and the second an alveolar tap or trill or semivowel. Nevertheless, these are part of the same phoneme in Parisian French and standard German. Other, even more illustrative, examples are the [v]/[w] and [f]/[ph] phone pairs of Hindi/Urdu. These are freely interchanged and have the same phonemic value, although they are obviously very different sounds. That is to say, in Hindi/Urdu, one can say phal or fal and still mean the same thing, “fruit”; or varshaa or warshaa, and still mean “rain”.
To put it another way, actual speech sounds are organized into different, and cross-cutting, significant sets in various languages: Citing the example above, p, whether aspirated or unaspirated, is the same phoneme in English, but the two versions belong to contrasting phonemes in Hindi, where (however) f is heard as the same sound as aspirated-p.
Why is it important for an alphabet (a script) to be able to convey information on phonemic idiosyncrasy?
To date, no practical world alphabet conveys phonemic information, let alone information on phonemic idiosyncrasy. Why is this important? Well, the expression of phonemic idiosyncrasy across languages must somehow be incorporated into and accommodated by a single writing system, a universal script, for reasons that will be clear from the sequel.
For example, an English speaker, when reading Hindi/Urdu in the universal script, should be able to immediately comprehend that the phone [v] can also be pronounced as a [w], although when reading English in the same universal script, [v] and [w] are pronounced quite differently. Similarly, a Hindi/Urdu speaker should immediately be able to comprehend, when reading English in the same universal script, that [p] and [ph] have the same value in English, unlike the case in his/her own language. As another example, an English speaker, when reading Arabic in the same script, should immediately be able to understand that [p] and [b] are not separate phonemes in Arabic, and such bilabial sounds are usually, but not always, pronounced as [b], the [p] being absent in nearly all (but not all) Arabic dialects. Etc. etc.. The universal script must contain and be able to convey this information. That is to say, a truly universal script must convey information on phonemic idiosyncrasy.
This is one of the reasons that finding a common script that accommodates both Hindi/Urdu (a North Indian, Indo-European-base language) and Tamil (a South Indian, Dravidian-base language) has proved so difficult. Attempts to write Tamil in the Dewanaagari script used for Hindi or the Arabic-base script used for Urdu, or to write Hindi/Urdu in the Tamil script, lead to insurmountable difficulties. For starters, it is difficult to express the fact that in Tamil, there is no phonemic distinction between aspirated and non-aspirated sounds.
Again, prior to Navlipi, no world script did this.
What are the main features of NAVLIPI?
NAVLIPI simply means “new script” in Sanskrit and the modern Sanskrit-base languages of India. Here are some features of NAVLIPI:
- It is based on the Roman (Latin) script. It uses just five new or transformed letters (glyphs) in addition to the 26 letters of the Roman script.
- In addition to being a phonemic script, NAVLIPI is also a precise phonetic (phonic) script that very accurately transcribes the sounds and features found in all the world’s languages. These include the more common features such as tones as well as the less common ones such as clicks, ejectives and implosives. It is thus applicable to all the world’s languages. It is capable of transcribing equally well a tonal language such as Mandarin and a click language such as !Xo Bushman, in an extremely “user-friendly”, intuitive and practical way.
- It is far more thorough, complete, distinct and practical than the alphabet of the International Phonetic Association (IPA) the Americanist alphabet, and other “universal” world scripts. It addresses the serious drawbacks and (some) errors of these scripts even in standard phonetic (i.e., non-phonemic) transcription. And of course, these other scripts/alphabets are not phonemic, but rather phonetic (phonic).
- NAVLIPI uses no cumbersome diacritics, rather making heavy use of “post-ops“, post-positional operators. A typical NAVLIPI post-op is , which indicates aspiration, e.g. as in p, the aspirated counterpart of the p sound. Another typical NAVLIPI post-op is (a subscripted infinity sign) which indicates a combination of unvoiced (as in the p sound) and voiced (as in the b sound) phones; this is useful for transcription in a language such as Mandarin, where unvoiced and voiced sounds are frequently part of the same phoneme (in this example transcribed as b).
How does NAVLIPI transcribe phonemic idiosyncrasy?
NAVLIPI transcribes phonemic idiosyncrasy in a very facile, intuitive manner, illustrated by the following examples:
- For the common (aspirate + non-aspirate) phoneme, NAVLIPI simply uses a subscripted circle, ₒ. Thus the /p/ phoneme of English of the example above, which includes the phones [p] and [ph], is simply transcribed as pₒ.
- For less common phonemes such as the one combining the [x] (uvular fricative) and [r] (trilled “r”) in Parisian French and Hochdeutsch German, or the one combining the v and w sounds in Hindi/Urdu, NAVLIPI simply uses compound letters (glyphs), here the digraphs xr and vw respectively.
- For the complex (voiced + unvoiced) phoneme present in most Chinese languages, NAVLIPI uses the post-op (a subscripted infinity sign) to indicate a combination of unvoiced (as in the p sound) and voiced (as in the b sound) phones. Thus, the bilabial Mandarin phoneme found in the word meaning “no” and pronounced both pu and bu is transcribed as b, as in the NAVLIPI transcription bu.
What does NAVLIPI Look Like?
Here are some examples of what NAVLIPI looks like for the five most widely spoken languages of the world (listed sequentially, in decreasing order of speakers, Mandarin, Hindi/Urdu, English, Arabic and Spanish):
Mandarin (Beijing)
你 不 认 识 他 吗 ?
N bu qnsh₀i taa, maa?
Legend:
- =3rd tone (falling, mid-to-low + rising, low-to-mid). This is an example of a NAVLIPI post-op, a post-positional operator, positioned after the phone it is describing (“operating on”).
- b indicates voiced + unvoiced, i.e. that this can be uttered as a b or a p sound without changing the meaning of the word. (This is an example of the transcription of phonemic idiosyncrasy in NAVLIPI.) (), the subscripted infinity sign, is another NAVLIPI post-op, indicating (voiced + unvoiced).
- = 2nd tone, rising mid-to-high.
- q = the sound of the e in English father.
- = 4th tone, falling high-to-low.
- sh₀ = the sound of the sh in English shoot.
- = aspirated t.
- aa= the sound of the a in English father.
- | = 1st tone, level, high.
Hindi/Urdu (standard, Khari Boli) in Dewanaagari alphabet
बच्चे खेलते रहे ।
bacce khₒƐltƐ rahƐ.
Legend:
- c = sound of ch in English child or of c in Italian duce; emulates Italian.
- khₒ = aspirated k.
- Ɛ = sound of é in English and French fiancé; distinguished from the e of English pet.
English, British pronunciation
beautiful, sunny day
bjₒiful, sani ₒƐi
Legend:
- j = sound of y in English yes.
- uu = long u.
- = alveolar plosive, the t sound of English stop, distinguished from the dental t sound of Spanish or Hindi/Urdu tu. In ₒ, the added subscripted circle indicates that this sound can be uttered unaspirated or aspirated, without changing the meaning of the word. (This is an example of the transcription of phonemic idiosyncrasy in NAVLIPI.)
- = alveolar plosive, the d sound of English wordy, distinguished from the dental d sound of Spanish diente or Italian dente or Hindi/Urdu daant. In ₒ, the added subscripted circle indicates that this sound can be uttered unaspirated or aspirated, without changing the meaning of the word. (This again is an example of the transcription of phonemic idiosyncrasy in NAVLIPI.)
- Other NAVLIPI letters already explained above.
Spanish, Madrid pronunciation
occurrido la semana pasada
okurrdo l sƐmn psd
Legend:
- aa= sound of a in English father.
- Other NAVLIPI letters already explained above.
Arabic, Egyptian, Cairo pronunciation
استيقظ الشاب الطويل القامة فجأة وكأنه يكمل آخر ماتبقى
ƆstƆjaak..ata esh₀bu awilu alk..amati FƆƆ:Ɔten wo knnu
jukmelu a: axƐrƆ mƆtƆbƆk..Ɔ
Legend:
- Ɔ = sound of a in English Jack or hat. One of the only five new letters (glyphs) of NAVLIPI, supplementing the 26 glyphs (letters) of the Roman (Latin) alphabet.
- k.. = pharyngeal/uvular k sound, usually transcribed into Roman script as q in current usage.
- b = indicates voiced + unvoiced, i.e. that this can technically be uttered as a b or a p sound without changing the meaning of the word; but more precisely, in most Arabic, the p sound simply does not exist. (This is an example of the transcription of phonemic idiosyncrasy in NAVLIPI.)
- t.. = the characteristic “pharyngealized” dental t sound of Arabic, of course phonemically distinguished from the “standard” dental t sound.
- : = the glottal stop, like the sound of the elided t of English Cockney lot of money, or of the ‘ in the original pronunciation of Hawaii’i.
- Other NAVLIPI letters already explained above.
Some More Features Of NAVLIPI To Get A Feel For It
Here are some more examples of NAVLIPI letters (glyphs) and usage that will give the reader a better idea of what NAVLIPI is all about; it is by no means comprehensive- for a more comprehensive review, the reader is referred to the detail found in the NAVLIPI book, Vol. I:
- New letters (glyphs): NAVLIPI has only five new letters (in addition to the 26 of the Roman/Latin alphabet), of which two will be used rarely, since they are not common in the world’s most widely used languages. The three that will be commonly used are:
- Ɔ , an “inverted-c“, used for the sound of a in English Jack or hat.
- Ω, the “omega”, borrowed from the Greek to represent the au in English caught. This is used to distinguish from the o of Spanish dos.
- , an “inverted-j”, to represent the sound of the j in English Jack or jet. Thus, in NAVLIPI, the modern Roman letter j reverts to its original use as found in German, Swedish, etc., representing the sound of y in English yes. (The ancient Roman of course simply used the i in place of the later j). (The letter y is then used in NAVLIPI to represent the u of French tu or the ϋ of German ϋblich, thus reverting to its very original, “y-grecque” usage. )
- Long and short vowels: Sticking to its objective of practical discretization, NAVLIPI recognizes only two vowel lengths, short and long, for most languages. It then simply doubles (reduplicates) the short vowel to represent the long one. Thus, i and ii are used to represent the vowels in English bit and beet respectively. The only exception here is for the vowel representing the a in English father. Since this is already represented in NAVLIPI by a double letter, aa, the long form of this vowel is transcribed aaₒ in NAVLIPI, i.e. using a subscripted “little-circle” as a post-op. Quite evidently, in the rare languages that phonemically distinguish between, e.g., short, medium and long vowels, a triplication can be used to represent these, e.g., as i, ii and iii.
- Phones related to the dental t and d sounds:
- (As already noted above), NAVLIPI uses to denote the alveolar unvoiced plosive, the t sound of English stop, to distinguish it from the dental t sound of Spanish or Hindi/Urdu tu.
- Similarly, it uses to denote the alveolar voiced plosive, the d sound of English dumb, or German das to distinguish it from the dental d sound of Spanish dos or Hindi/Urdu do. The dt in fact emulates some German and Swedish transcriptions, (e.g. in Brandt), which were originally intended to distinguish from the Latin, pure dental d.
- Similarly uses (letter t with strikethrough) to represent the retroflex (tongue curled back), unvoiced plosive found in Indian subcontinent languages (e.g. in Hindi/Urdu taeni, “branch/twig”, transcribed in NAVLIPI as eeni). And the corresponding voiced retroflex plosive is rendered (the letter d with double strikethrough), as in the NAVLIPI transcription of the Hindi/Urdu word that means “box”, abbaa.
- Flaps or taps are non-vowel sounds uttered with a fleeting, light flapping or tapping of the tongue at the articulation position, rather than a full closure followed by an explosion of the breath, as in a plosive. These are very characteristic of the Indian subcontinent languages. To represent these retroflex flaps, which are currently rendered in Dewanaagari script by adding a diacritic, a dot, under the Dewanaagari letter, NAVLIPI uses the post-op (.), i.e. a single dot. It thus, in a sense, emulates the Dewanaagari tanscription, but using a post-op rather than a diacritic. Thus, the unvoiced and voiced retroflex flaps are rendered . and . respectively, in NAVLIPI.
- Thus, in place of the two letters t and d available in the Roman/Latin script to represent all these eight phones, NAVLIPI uses eight distinct glyphs: t, , , ., d, , and . . And of course, further, NAVLIPI transcribes phonemic idiosyncrasy in the Germanic and the South Indian Dravidian-base languages, most of which don’t distinguish phonemically between aspirate and non-aspirate. Thus, when one types the letter t in the NAVLIPI English/W. European or Tamil keyboards, it automatically comes out as tₒ, which means it can be pronounced as a t or a th sound.
- Uvular and pharyngeal sounds:
- To represent uvular (or rarely, pharyngeal) plosives, e.g. as found in Arabic (e.g. the uvular unvoiced plosive transcribed in Roman script as q, as in Al Qaeda), NAVLIPI uses a simple post-op, a double dot (..), operating on the corresponding velar plosive. Thus, the q of Arabic is rendered k.. in NAVLIPI.
- Similarly, the “pharyngealized dental” sounds, such as the t in Arabic kitaab (“book”), are also rendered with a double dot post-op.
- Some common and less common post-ops:
- As also already noted above, the post-op for aspiration is , i.e. the letter h with an added, subscripted little-circle. This emulates current Roman transcription (e.g. ph vs. p), but at the same time distinguishes from the letter h. Thus, the aspirated, unvoiced velar, dental and bilabial plosives are rendered, respectively, as k, t and p, respectively in NAVLIPI.
- Similarly, the post-op for fricatization is i.e. the letter h with an added, subscripted oval. This post-op would again be used with (i.e. operate on) the corresponding plosive. Thus, the dental fricative sound of the th in the British and American (but not Indian!) English pronunciation of thin is simply transcribed t in NAVLIPI.
- To represent clicks, NAVLIPI simply uses the post-op , i.e. the letter z with strikethrough. Thus, the lateral “giddyap” click, which is related to the l-sound, is simply rendered as l, whilst the dental click, the sound represented as “tsk tsk” in English is simply rendered as t.
- Some other common phones and phonemes:
- c is used to represent the sound of the ch in English child or of the c in Italian duce. As noted above, this borrows from the Italian.
- As noted above, ε is used to represent the sound of the a in English hay, whilst e is retained solely for the e of English pet. The long form of the latter vowel, as in English fair, is then simply represented by a reduplication of this letter, i.e. ee. Thus, in NAVLIPI, English fair would be transcribed as feer.
- sh₀ is used to represent the sound of the sh in English sheet. This attempts to accommodate the common English usage, at the same time using the post-op h₀ to indicate that this is a fricative sound. (Clearly, it does not strictly abide by NAVLIPI notation, since sh₀ would technically imply fricatization of the s sound, which is already a fricative.) In a similar manner, zh₀ is used to represent the sound of the s in English pleasure.
- x is used to represent the velar fricative, the ch of German doch or the kh of Arabic khilaaf (“against”). This is again in line with usage found in many modern Roman transcriptions.
- r is used to represent the lateral phone variously pronounced as a trill, a semi-vowel or a flap/tap in different languages. In nearly all widely spoken languages, the r is actually a phonemic condensate, representing at least these three phones. Nevertheless, NAVLIPI still uses separate letters to distinguish the central trill, tap/flap and semi-vowel.
- To represent nasalization of a vowel, NAVLIPI offers two options: (1) The use of the tilde (~), but used as a post-op rather than a diacritic. (2) The post-ops n₀ or m₀. Thus the French non could be transcribed in NAVLIPI as no~ or non₀ or, optionally, nom₀. (In common French pronunciations, a more accurate transcription may be n~, but that is another matter.)
- Many West African languages, e.g. Igbo, phonemically distinguish between bilabial sounds and corresponding “velarized” bilabial sounds. In common Roman transcription, these pairs of sounds are usually transcribed as p and kp, b and gb, etc. However, in more accurate phonetic transcriptions found in many phonetic alphabets, the digraphs (e.g. k and p) are connected with a curved line underneath them to show that they represent a single, velarized sound, rather than two distinct phones. NAVLIPI retains the former, simpler Roman transcription (i.e. without the curved underline, which would be a diacritic), as it posits that any reader reading these languages in the universal script will be well aware of the unique velarized phones found in them, and will thus recognize kp and gb etc.
- Transcription of tones: In NAVLIPI, tones are represented as post-ops. Three of the Mandarin tones were already used and explained in the short passage transcription above, and Mandarin provides a useful exemplar for elaboration of the NAVLIPI system of transcribing tones again. The post-ops used by NAVLIPI to transcribe the four tones of Mandarin are shown below. It is seen that the post-ops are meant to be graphical representations of the tones. E.g., the 2nd tone, “rising, mid-to-high”, has a 45° angle up-slope terminating in a short, upward hook.
- 1st tone, level, high: |
- 2nd tone: Rising, mid to high:
- 3rd tone: Falling (mid-to-low) + rising (low-to-mid):
- 4th tone: Falling, high-to-low:
- Keyboarding: More detail on the NAVLIPI keyboards is available on the FREE NAVLIPI KEYBOARDING SOFTWARE page on this site. Briefly, however, NAVLIPI keyboarding has the following salient features:
- The software at present comes as the following five (5) different, language-specific “keyboards”. (Additional keyboards, e.g. one for West African languages, will be added in the future.) These keyboards are all usable simultaneously once the software is installed and the user can freely toggle between them at will. These keyboards are pre-selected from a menu prior to starting to type. This selection is made outside the word processor. Each keyboard is further available in five (5) “fonts”, approximating Times New Roman, Arial, Courier, Calibri and a Script-type font. These further fonts are selected from the font menu within the word processor, much as one might select Arial or Times New Roman in Word. One can also of course select the font size for the font chosen, again from the word processor’s menu, as done normally with other fonts. The five (5) language-specific keyboards are:
- English/West European: Applicable to all non-Romance languages of Europe (e.g. German, Russian, Hungarian and isolates such as Basque).
- Hindi/Spanish: Applicable to all languages of the northern part of the Indian subcontinent, including Pushtu, Dari and the non-Indo-European “tribal” languages, and to Faarsi (Persian), Baloch (Baluchi), Kurdish, and other Indo-European languages of the near East. It is also applicable to all Romance languages of Europe and to Greek.
- Mandarin/Cantonese: Applicable to all Sino-Tibetan languages.
- Arabic: Applicable to Arabic, Hebrew, Amharic and related languages.
- Tamil: Applicable to all Dravidian languages of the southern part of the Indian subcontinent and to Singhalese. Also applicable to non-Dravidian “tribal” South Indian languages.
- The software at present comes as the following five (5) different, language-specific “keyboards”. (Additional keyboards, e.g. one for West African languages, will be added in the future.) These keyboards are all usable simultaneously once the software is installed and the user can freely toggle between them at will. These keyboards are pre-selected from a menu prior to starting to type. This selection is made outside the word processor. Each keyboard is further available in five (5) “fonts”, approximating Times New Roman, Arial, Courier, Calibri and a Script-type font. These further fonts are selected from the font menu within the word processor, much as one might select Arial or Times New Roman in Word. One can also of course select the font size for the font chosen, again from the word processor’s menu, as done normally with other fonts. The five (5) language-specific keyboards are: